
WHAT IS DBT TOOL?
Before we load our data into the data warehouse or data lake, we have to do some transformations like cleaning the data, keeping up the consistency of the data, etc…, Basically the “T” in ETL/ELT (extract, load, transform) process. This helps the analytics team to provide perfect numbers to the stakeholders.
DBT is the tool that helps data engineers or analysts to perform transformations on the data in their warehouse more efficiently. It fulfills the transform phase in the ETL/ELT process.
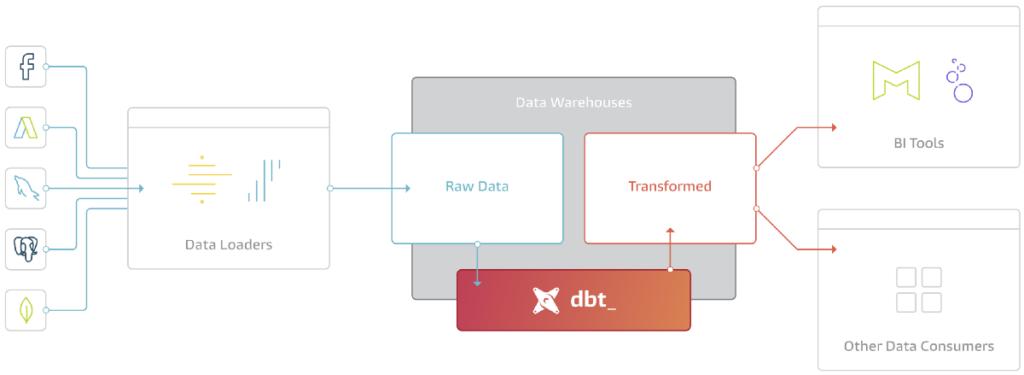
DBT finally brought the software engineering best practices like testing, version control, and documentation. In DBT a data engineer can perform transformations on the data in their warehouse using select statements in SQL. DBT converts the SQL select statements into tables and views.
WHAT IS AZURE DATABRICKS?
Databricks is a cloud-based tool that helps data engineers process and performs transformations and explores large quantities of data efficiently with ease. It plays a good role in ETL/ELT processes for a data engineer or analyst. Databricks are built on top of distributed Cloud computing environments like Azure, AWS, or Google Cloud that facilitate running applications on CPUs or GPUs based on analysis requirements. Databricks platform is said to be much faster than Apache Spark. It enhances innovation and development and provides better security options. It comes with inbuilt data visualization tools.
DBT cloud and Azure Databricks Integration:
Step 1: Sign up for a DBT cloud account if do not have one. One can create a cloud DBT account at https://cloud.getdbt.com.
Step2: Create a DBT project
1. Click on Begin after signing in or click on the three stripes and select Account settings
2. Clik “New Project” and then Begin with giving the name of the Project and then continue
3. In the next step select “Databricks” to establish the connection with databricks cluster or SQL endpoint.
4. Connection with the cluster.
- Give a name to the connection.
- Leave the method as ODBC in the method dropdown menu.
- For Hostname and Port value under the advanced options go to JDBC/ODBC tab in your cluster
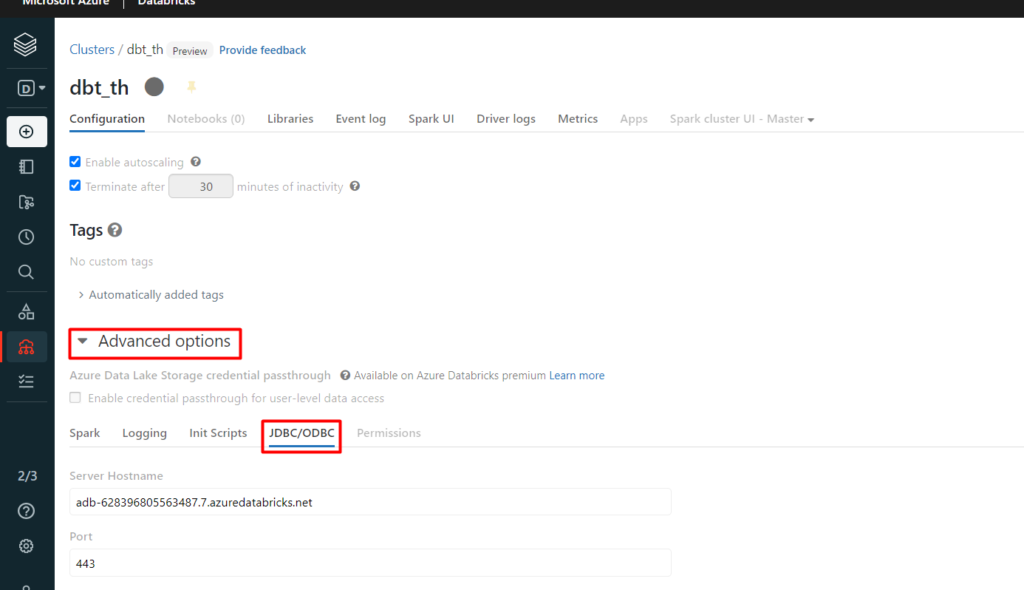
- We can leave the organization empty.
- For Cluster, value copies the value after the last forward slash character in the HTTP path in the same JDBC/ODBC tab under the advanced options in your cluster.
- We can also leave the user and endpoint values empty.
- For Token go to your user setting in databricks, under Access tokens you can generate a personal access token if not having one currently and provide the generated token in the token tab of DBT.
- In Schema provide the name of the database where you want to store your tables or views created
- Click on test connections at the top after providing all required information, after clicking on continue if the test is successful.
Step3: After successfully establishing the connection create a repo based on requirements.
Now let’s see a small demo of how the connection works
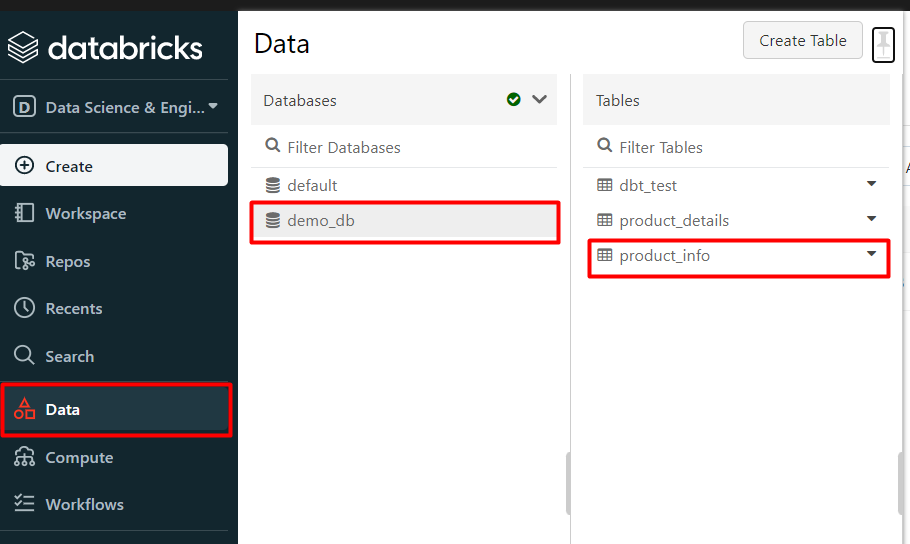
In this demo, we will see how to create tables and views in DBT cloud IDE using select statements. First, we need to create a table in the data bricks datasets. I have created a demo table as product_details under my demo_db database in the data bricks dataset.

Step1: Click initialize your project.
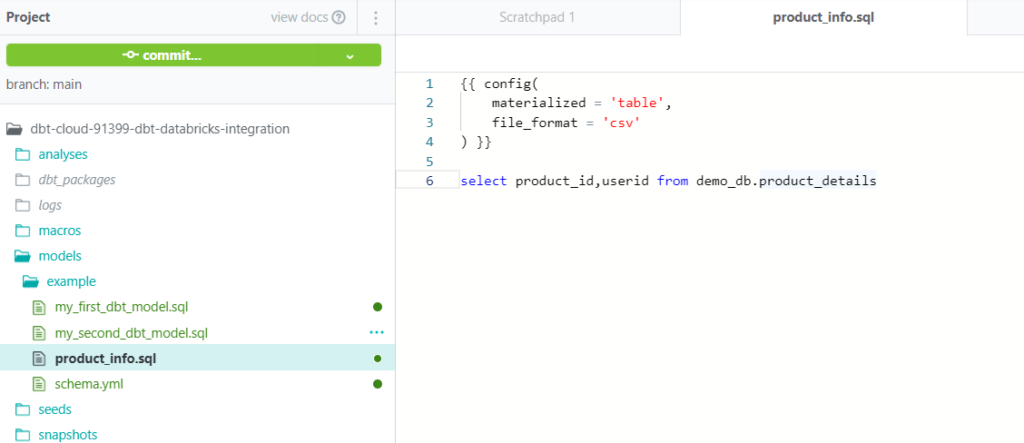
Step2: Create a new SQL file under the model’s file which creates a model with the file name provided and write a SQL query with a select statement as below and save it, which creates a table/view under the provided database in databricks
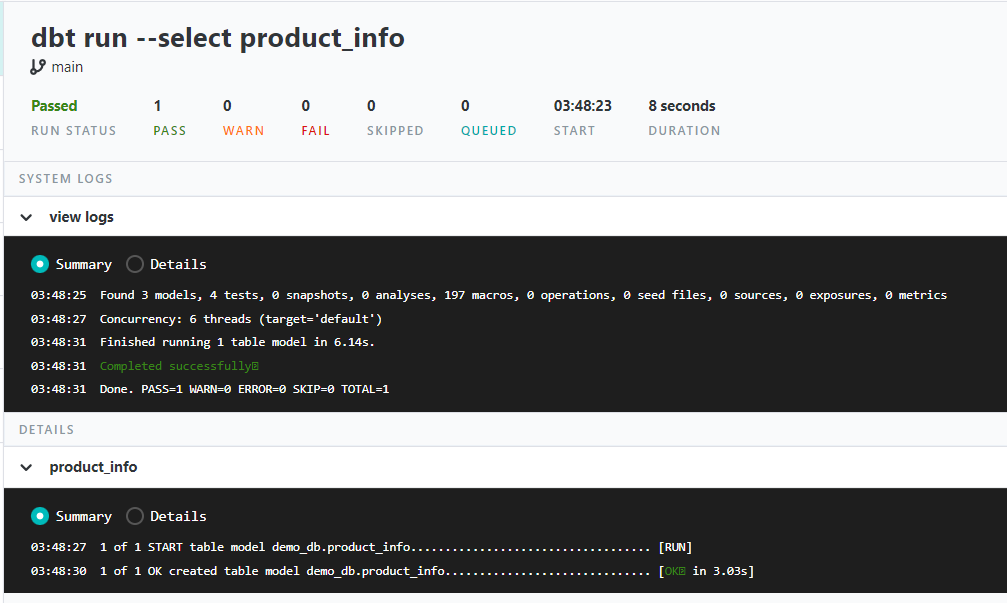
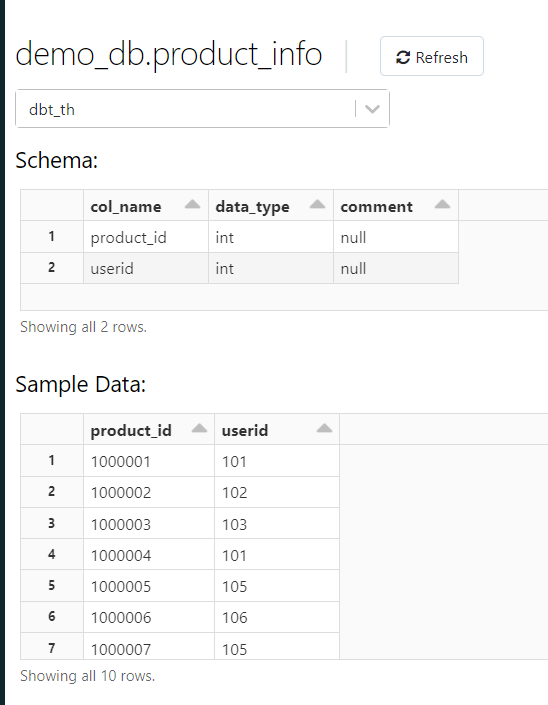
Step3: Run the model using the command “dbt run –select model_name”. (product_info in my use case is the model_name)
After executing the above run it creates a table/view under the provided database in databricks, DBT also gives us the logs for the above run in the terminal as below.
Result in the databricks database after the run:
Conclusion:
In such a simple way we can integrate the databricks with the DBT cloud and can perform any kind of transformations using simple SELECT statements to create tables/views.